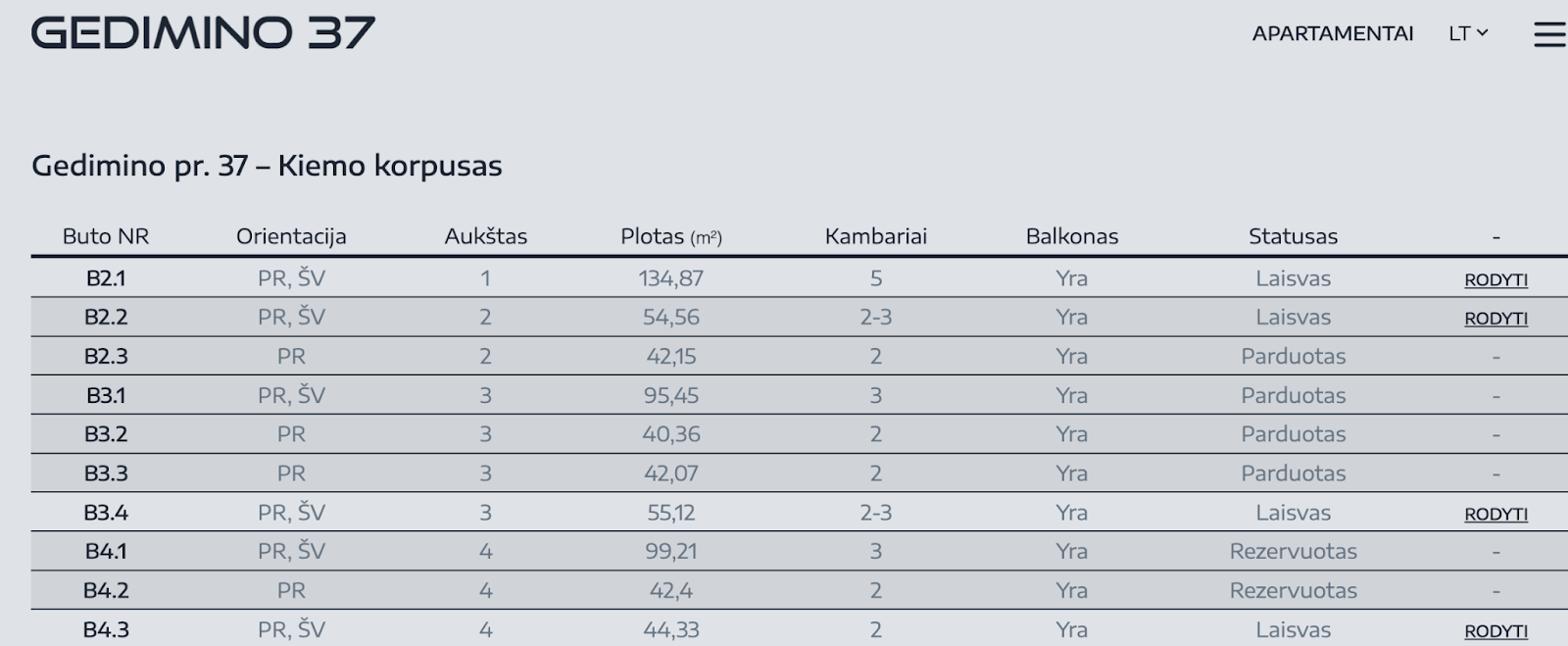
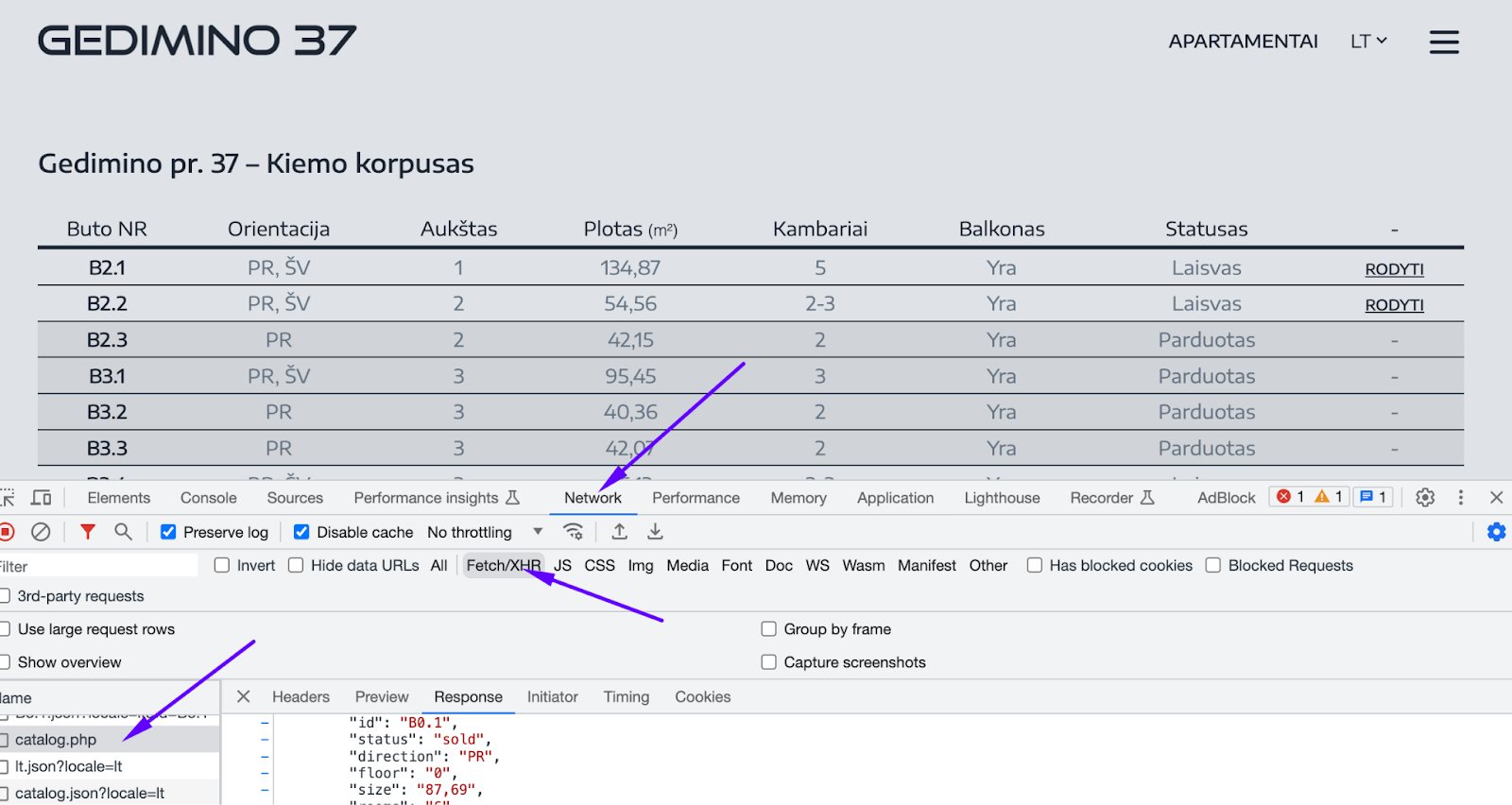
Sometimes data stored in memory can become very large, for example the pattern of pagination here:
# ssva.lt energinio naudingumo registras
# from pprint import pprint
import re
import json
from dphelper import DPHelper
helper = DPHelper(is_verbose=True)
headers = helper.create_headers(authority='ssva.lt')
def generate_url(page_number, PAGE_SIZE=10000):
return f'https://www.ssva.lt/registrai/pensreg/pensert_list.php?goto={page_number}&pagesize={PAGE_SIZE}'
PAGINATION_DATA_PATTERN = ('Toliau</a></li>.*?pageNum="(.*?)" >Pabaiga</a>')
DATA_PATTERN = (
'<tr id="gridRow.*?class="r-gridrow">'
'<tddata-record-id=".*?".*?SertifikatoNr".*?val="(.*?)" >' # sert nr
'.*?"IsdavimoD".*?val="(.*?)" >' # isdavimo data
'.*?GaliojimoD".*?val="(.*?)" >' # galiojimo data
'.*?UnikalusNr".*?val="(.*?)" >' # unikalus nr
'.*?Adresas".*?val="(.*?)" >' # adresas
'.*?Paskirtis.*?val="(.*?)" >' # paskirtis
'.*?PEN".*?val="(.*?)" >' # PEN
'.*?Ap" >.*?val="(.*?)" >' # sildomas plotas
'.*?Q".*?val="(.*?)" >' # E.sanaudos
'.*?Hsrc".*?val="(.*?)" >' # silumos saltinis
'.*?Pastaba".*?val="(.*?)" ></span></span></td></tr>' # pastaba
)
def get_page_count():
FIRST_PAGE_URL = generate_url(1)
raw_content = helper.from_url(FIRST_PAGE_URL, headers=headers)
rg = re.compile(PAGINATION_DATA_PATTERN)
last_page_nr = rg.findall(raw_content)
return int(last_page_nr[0])
if __name__ == "__main__":
last_page_nr = get_page_count()
# Compile is slow, so we do it once
rg = re.compile(DATA_PATTERN)
data = []
for page_number in range(1, last_page_nr + 1):
url_for_read = generate_url(page_number)
# print(url_for_read)
page_content = helper.from_url(url_for_read, headers=headers)
results = rg.findall(page_content)
data.extend(results)
print(json.dumps(results, indent=2))
print(json.dumps(data, indent=2))
In such scenarios it can be useful to define this as streamin g response from json_stream pip package. Basic example:
import sys
import json
from json_stream import streamable_list
def test_stream():
for i in range(20):
yield i
# wrap existing iterable
data = streamable_list(test_stream())
# consume iterable with standard json.dump()
json.dump(data, sys.stdout)Applying example to this scenario:
# ssva.lt energinio naudingumo registras
# from pprint import pprint
import re
import json
import sys
from dphelper import DPHelper
from json_stream import streamable_list
helper = DPHelper(is_verbose=True)
headers = helper.create_headers(authority='ssva.lt')
def generate_url(page_number, PAGE_SIZE=100):
return f'https://www.ssva.lt/registrai/pensreg/pensert_list.php?goto={page_number}&pagesize={PAGE_SIZE}'
PAGINATION_DATA_PATTERN = ('Toliau</a></li>.*?pageNum="(.*?)" >Pabaiga</a>')
DATA_PATTERN = (
'<tr id="gridRow.*?class="r-gridrow">'
'<tddata-record-id=".*?".*?SertifikatoNr".*?val="(.*?)" >' # sert nr
'.*?"IsdavimoD".*?val="(.*?)" >' # isdavimo data
'.*?GaliojimoD".*?val="(.*?)" >' # galiojimo data
'.*?UnikalusNr".*?val="(.*?)" >' # unikalus nr
'.*?Adresas".*?val="(.*?)" >' # adresas
'.*?Paskirtis.*?val="(.*?)" >' # paskirtis
'.*?PEN".*?val="(.*?)" >' # PEN
'.*?Ap" >.*?val="(.*?)" >' # sildomas plotas
'.*?Q".*?val="(.*?)" >' # E.sanaudos
'.*?Hsrc".*?val="(.*?)" >' # silumos saltinis
'.*?Pastaba".*?val="(.*?)" ></span></span></td></tr>' # pastaba
)
def get_page_count():
FIRST_PAGE_URL = generate_url(1)
raw_content = helper.from_url(FIRST_PAGE_URL, headers=headers)
rg = re.compile(PAGINATION_DATA_PATTERN)
last_page_nr = rg.findall(raw_content)
return int(last_page_nr[0])
def yield_data():
last_page_nr = get_page_count()
rg = re.compile(DATA_PATTERN)
last_page_nr = 5
for page_number in range(1, last_page_nr + 1):
url_for_read = generate_url(page_number)
page_content = helper.from_url(url_for_read, headers=headers)
results = rg.findall(page_content)
for result in results:
yield result
if __name__ == "__main__":
# wrap existing iterable
data = streamable_list(yield_data())
# consume iterable with standard json.dump()
json.dump(data, sys.stdout)