Category: Platform workflow
How to work most efficiently
Debugging
Lost why your pipeline breaks? Add print statement (typically combining with existing program immediately, for example by throwing exception):
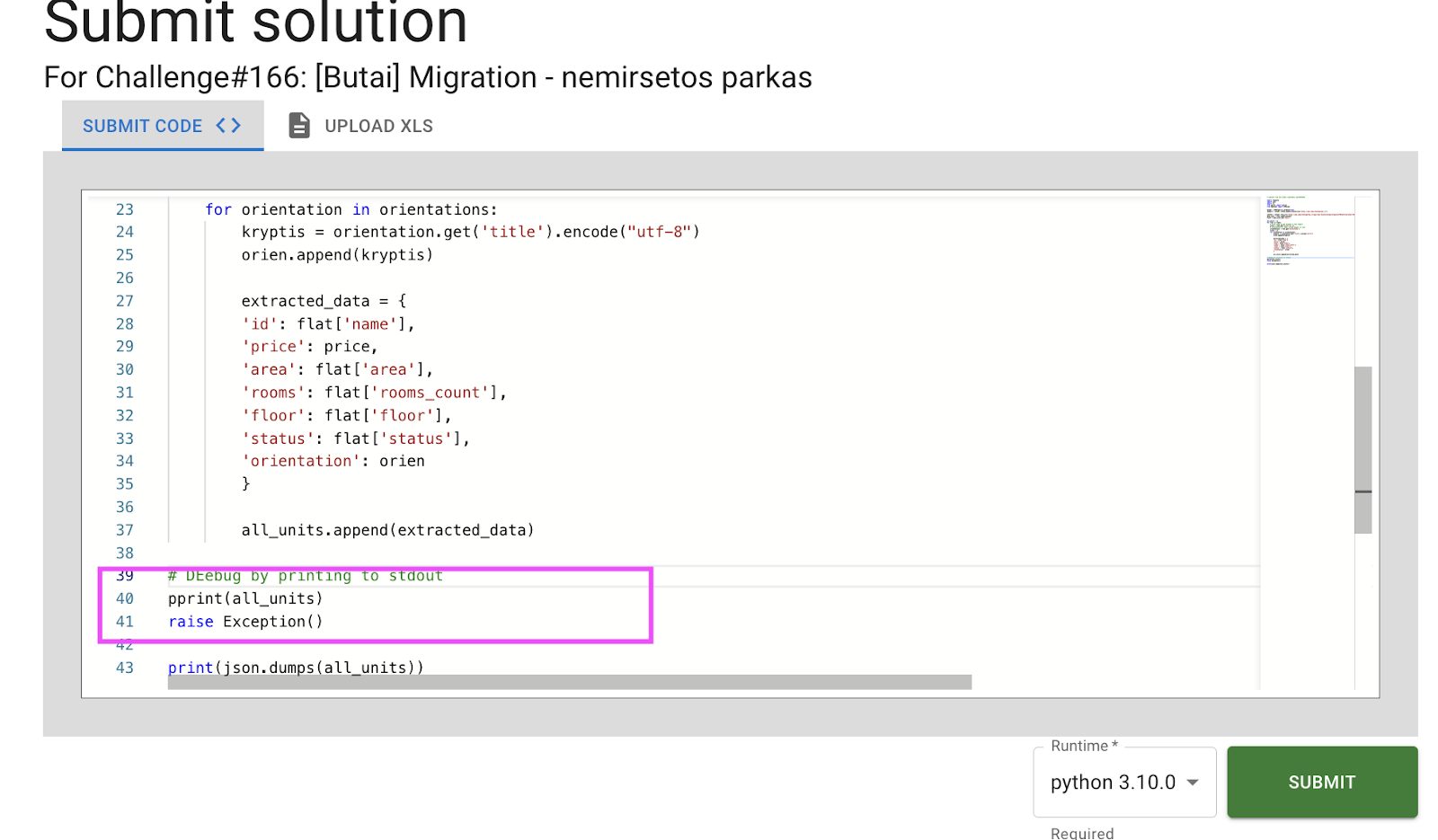 |
Now check intermediate print results shown in output
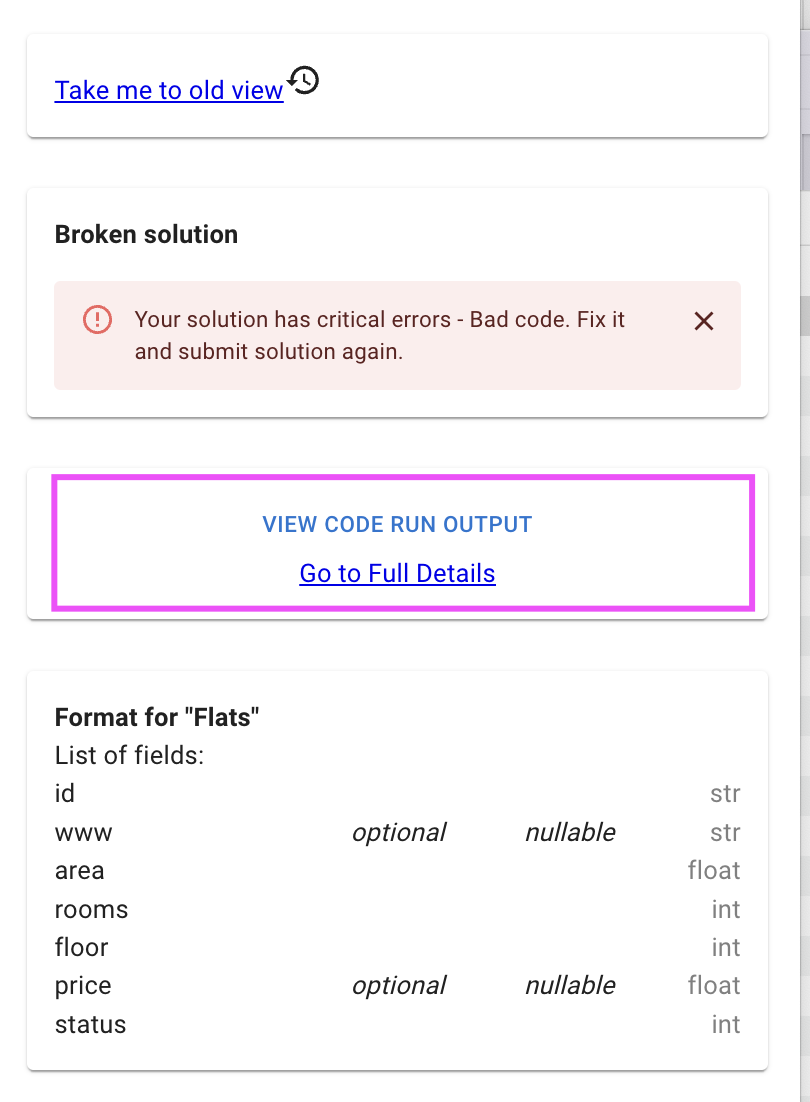
Another approach to debug is simply use stderr to print intermediate debug output. The pattern is as following:
import sys
print('This is an error message', file=sys.stderr)
# Output:
# This is an error messageTip: data platform will only read sys.stdout as an output. You can use this as afeature: if you need to have some print statements (for example, statistics of each step in pipeline), you can route them to stderr.
Introduction
The goal of our platform is to match business with data engineering specialists who can help gather data for better decisions.
For you, as platform contributor, the entire process looks like this. First, you choose one of the data challenges. To make sure you have enough time to asses and attempt the task, we allow you to reserve it for 72 hours so that it is not shown to other contributors.
You then will have to create program which will output data in structured format into standard output (i.e. using print statement). When you are done, you will use our code submission tool to verify your program delivers results in format we expect. If result is approved by validation, we will manually review your solution, if any other minor adjustments are needed. After your solution passes required quality bar, you will be rewarded payout which will accumulate into your account.
To make your start easier, you can use our helper libraries, use examples. In case you have question or need mentoring, you can reach out to support via in product chat.
Choosing a challenge
First, open the platform using your credentials and go to section “I can sell data”. Review descriptions of each task, assess your skill, as well as rewards system and choose one which fits you most.
Challenges differ by this criteria:
Schema
Each schema defines differen structure of data.
Payout
Each task may have different reward
Subtype
Some challenges require to create solution from scratch, while others require to fix or adjust existing code (pipeline which broke)
Writing solution for challenge
Lets say the data challenge is to extract data from ecommerce site with product ids and pricing information. Thus the schema may look like this:
| Field name | Field type |
| product_id | INTEGER (REQUIRED) |
| price | FLOAT (REQUIRED) |
An example of very basic program (in Python) which just prints hardcoded values in required format looks like this:
import json
data = [
{‘product_id’: ‘iphone_10’, ‘price’: 119.99},
[‘product_id’: ‘iphone_11’, ‘price’: 159.99},
]
print(json.dumps(data))This would be accepted by platform, but of course the idea that data is real and up to date. Therefore your code rather should fetch HTML content, extract required data and structure in required format.
import json
import requests
response = requests.get(‘http://www.iphones.lt’)
# models and prices stored in HTML table
rg = re.compile('<tr><td>(.*?)<td><td>(.*?)</td></tr>’)
results = rg.findall(response.content)
data = []
for model_str, price_str in results:
data.append({
‘product_id’: model_str,
‘price’: float(price_str)
})
print(json.dumps(data))The key part is that your last part where you print JSON serialized data into standard output using regular print statement. Don’t forget to serialize it using json.dumps()! Typically, the program shall use json.dumps(data) only once to ensure output in JSON format.
print(json.dumps(data))Warning: don’f forget to remove your debugging prints as it will result in invalid data.
Tip: Go to section Utils to learn how to make processing even easier.
Submiting solution
After you finished building solution on your computer or remote development server, time to submit the code!
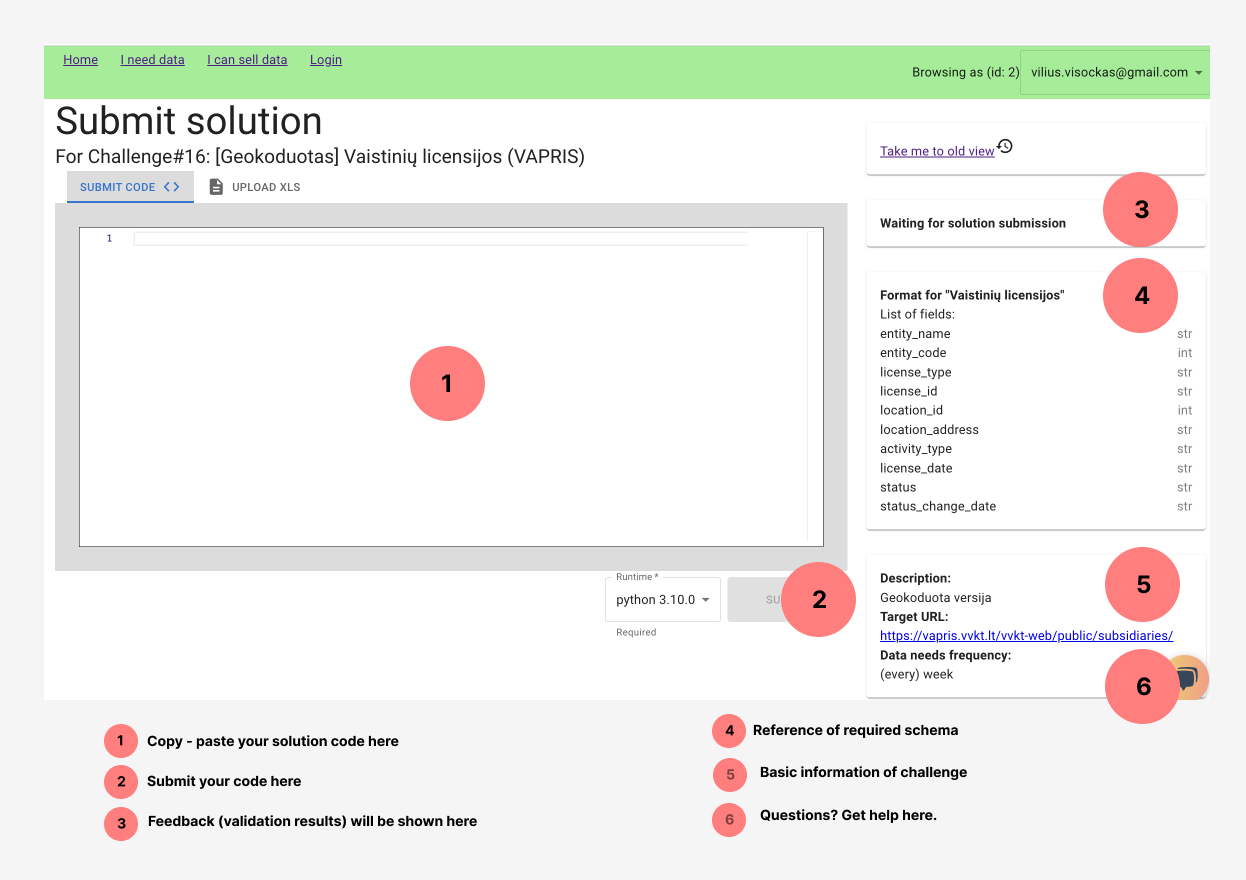
Code submission flow. On the left of the screen you can see code editor, while on the right you will immediately get feedback about your solution.
Solution review
When validation passes, our experts will review your solution and schedule to run it automatically. If needed, though, we may reach out to you and ask to minor adjustments to fit our quality bar.
Below are the stages for review:
| Stage | Description |
| Validators | Your code output is run through validators for particular data type. Warning level may be accepted, however code with errors will not be flagged for review in next stage |
| Data spot check | Data produced by program is compared with data on target website by performing random spot checks as well as checking column quality and number of rows matches. |
| Code review | If data quality is good, we inspect code and make sure it uses best practises and will work longer term without breaking |
| Resource optimization | If code uses to much memory, compute power of third party apps, we will look into ways to make your pipeline more efficient to reduce our cost basis. |
Claiming your rewards
After your solution passes the quality bar defined by platform, we will add it to your account. At the moment we process rewards when they accumulate over 100 euros.
Maintaining solution
It is likely that your solution may break at some point in the future for external factors (for example, website design changes). At the moment we don’t expect you to fix these issues, but we are working on reward system for maintaining your pipelines healthy.
If pipeline breaks however, our team will create a new task (challenge) with a dedicated budget to get it fixed.