In case you need to normalize data, write multiple pipelines: first, the one which scrapes original data unformatted. Then write extra pipeline which normalizes data from previous pipeline.
This way you can always fix problems ar adjust normalization for older datasets (no data is lost)
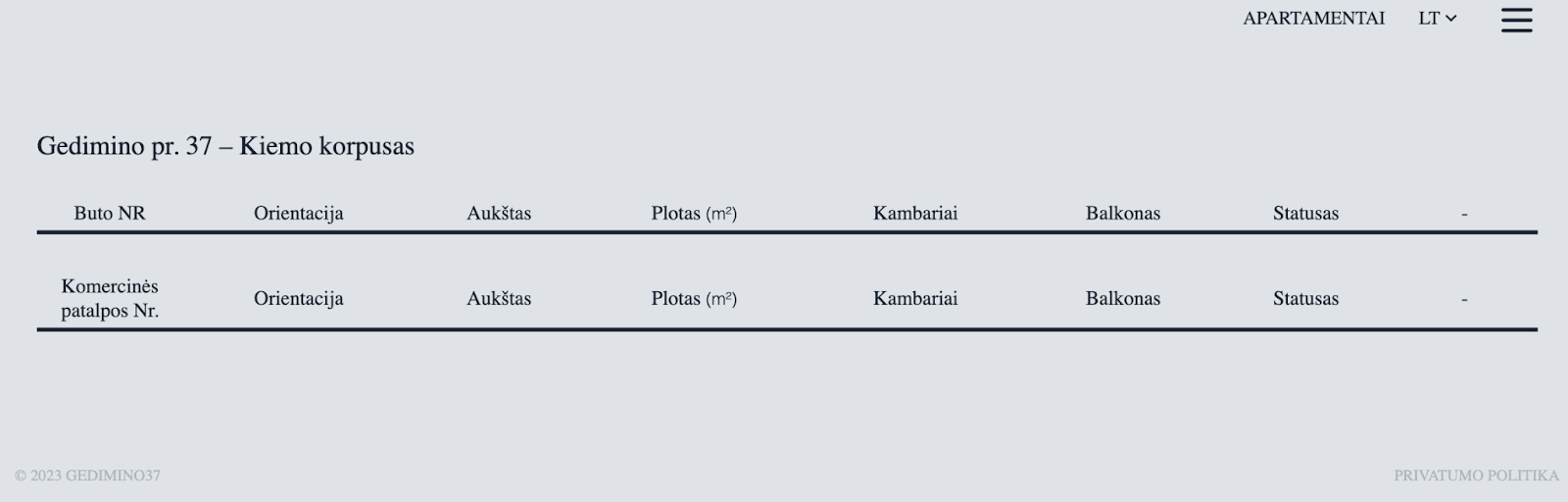
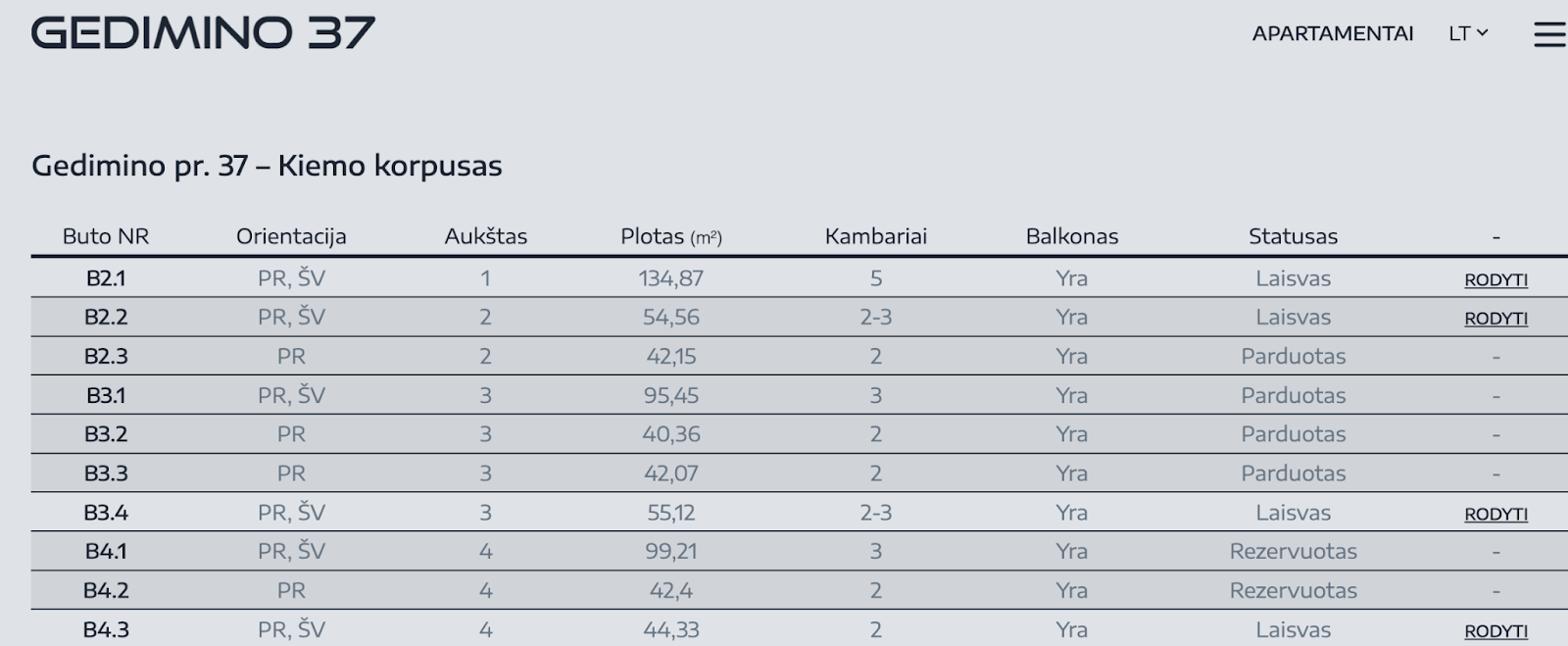
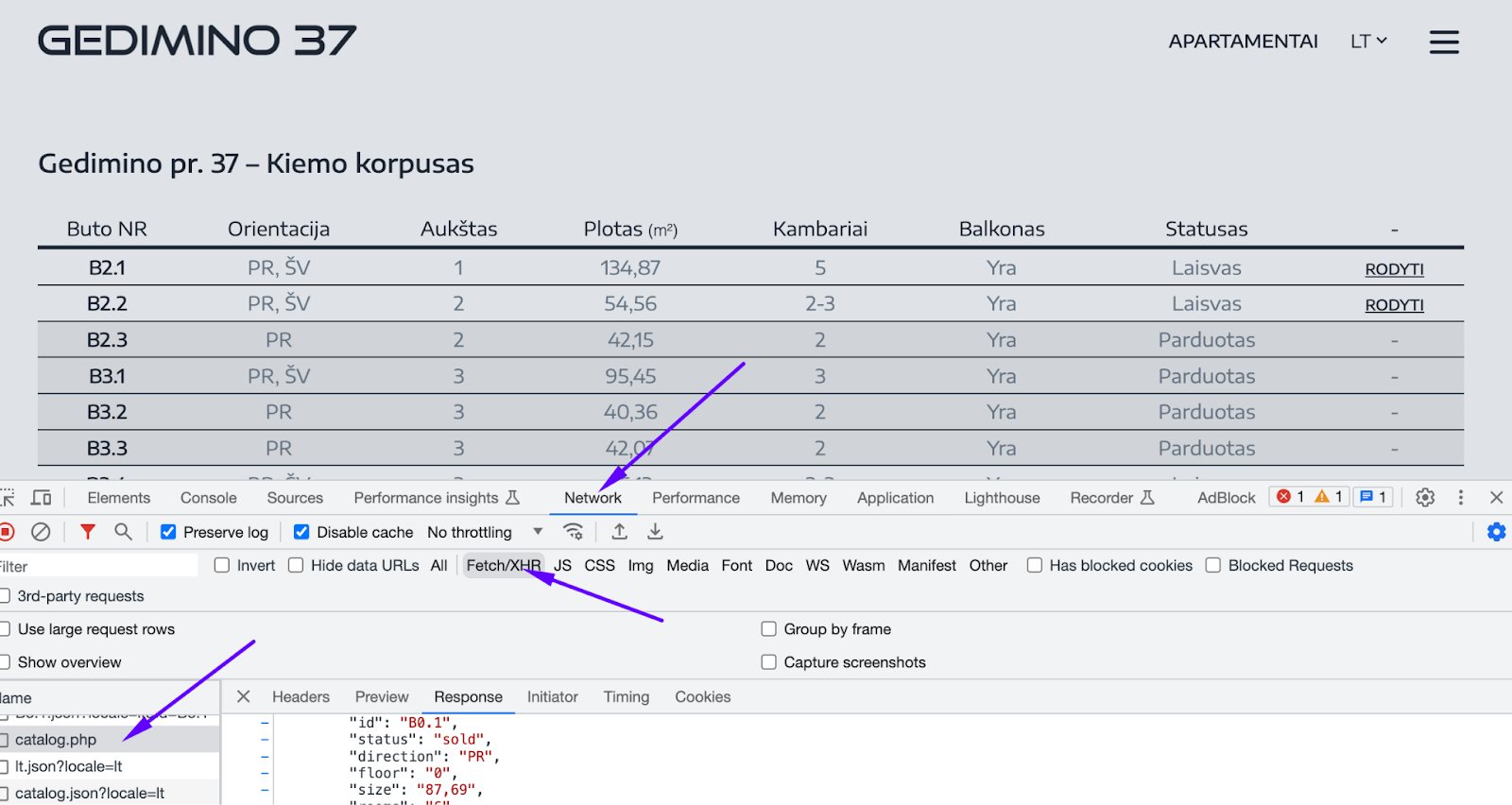
Sometimes data for web page is loaded dynamically, i.e. on demand. This can be done for performance reasons, to make initial load faster. Sometimes you can identify this pattern by observing spinners or loaders, or content appearing incrementally:
On the browser, this can be observed by inspecting Network tab of debugger tools. For example, on Chrome, you can find Network tab by clicking on menu “View > Developer > Developer Tools” and going into Network tab
The goal of our platform is to match business with data engineering specialists who can help gather data for better decisions.
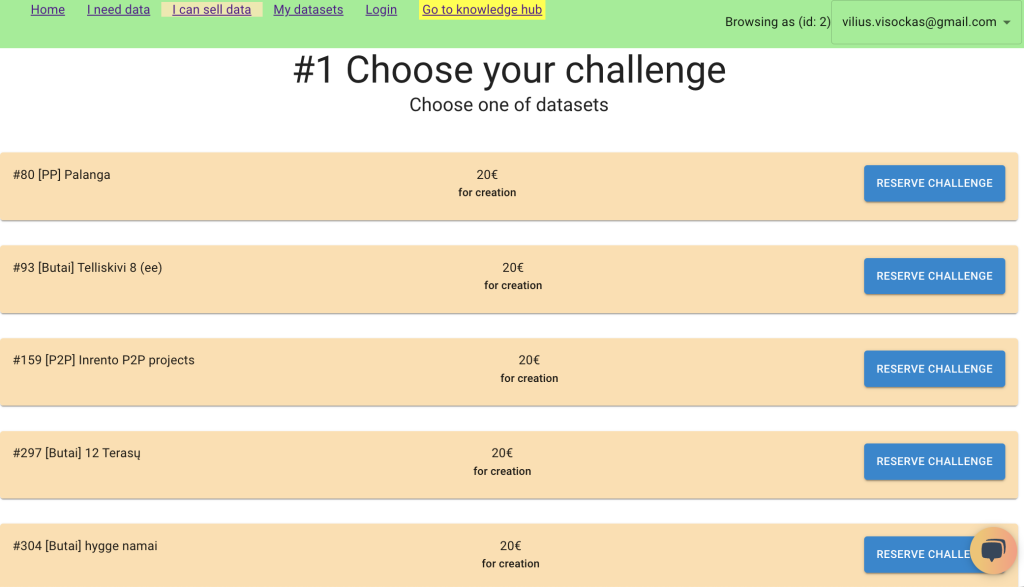
For you, as platform contributor, the entire process looks like this. First, you choose one of the data challenges. To make sure you have enough time to asses and attempt the task, we allow you to reserve it for 72 hours so that it is not shown to other contributors.
You then will have to create program which will output data in structured format into standard output (i.e. using print statement). When you are done, you will use our code submission tool to verify your program delivers results in format we expect. If result is approved by validation, we will manually review your solution, if any other minor adjustments are needed. After your solution passes required quality bar, you will be rewarded payout which will accumulate into your account.
To make your start easier, you can use our helper libraries, use examples. In case you have question or need mentoring, you can reach out to support via in product chat.
First, open the platform using your credentials and go to section “I can sell data”. Review descriptions of each task, assess your skill, as well as rewards system and choose one which fits you most.
Challenges differ by this criteria:
Schema
Each schema defines differen structure of data.
Payout
Each task may have different reward
Subtype
Some challenges require to create solution from scratch, while others require to fix or adjust existing code (pipeline which broke)
This would be accepted by platform, but of course the idea that data is real and up to date. Therefore your code rather should fetch HTML content, extract required data and structure in required format.
import json
import requests
response = requests.get(‘http://www.iphones.lt’)
# models and prices stored in HTML table
rg = re.compile('<tr><td>(.*?)<td><td>(.*?)</td></tr>’)
results = rg.findall(response.content)
data = []
for model_str, price_str in results:
data.append({
‘product_id’: model_str,
‘price’: float(price_str)
})
print(json.dumps(data))
The key part is that your last part where you print JSON serialized data into standard output using regular print statement. Don’t forget to serialize it using json.dumps()! Typically, the program shall use json.dumps(data) only once to ensure output in JSON format.
print(json.dumps(data))
Warning: don’f forget to remove your debugging prints as it will result in invalid data.
Tip: Go to section Utils to learn how to make processing even easier.